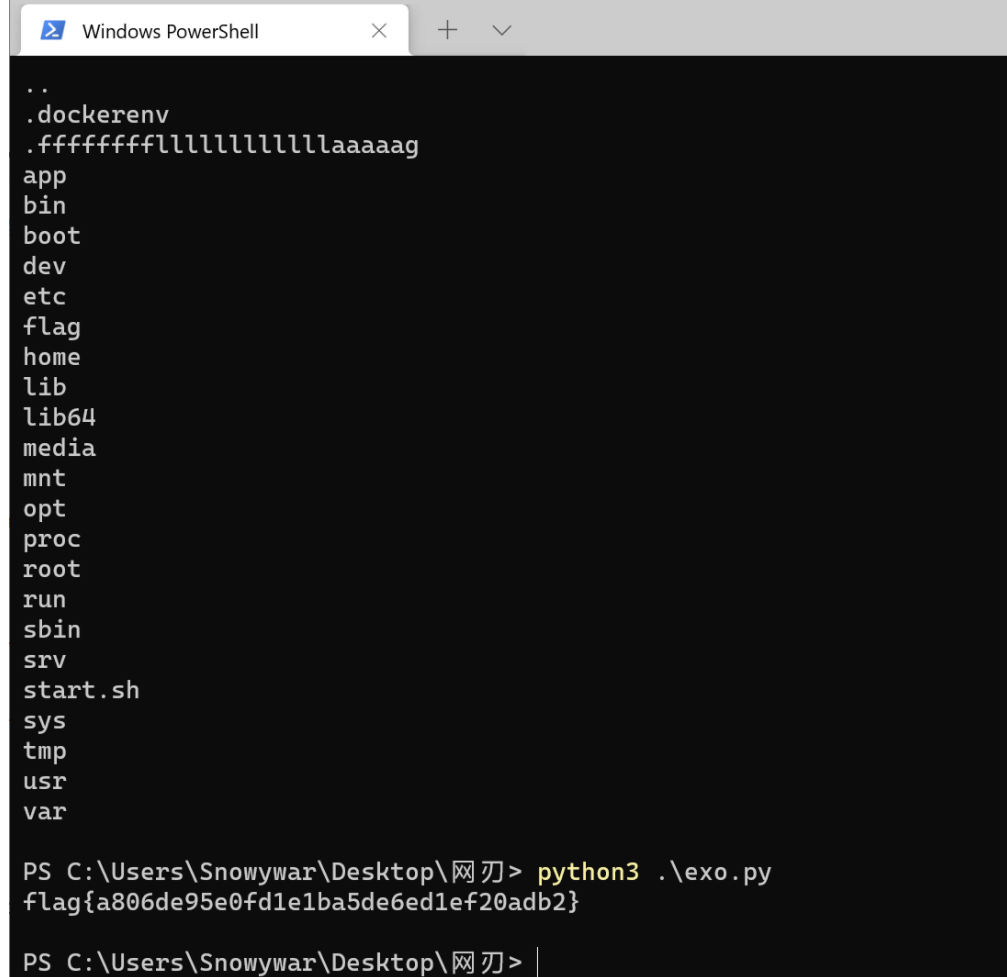

大家都知道我最喜欢的ctf类型就是misc了,现在我已经ak了取证版本的misc,流量版本的misc,内存版本的misc,脑洞版本的misc,图片版本的misc,音频版本的misc,隐写版本的misc,套娃版本的misc,傻逼版本的misc,套神版本的misc,八神版本的misc,但我还没有ak编曲版本的misc,今天来ak一个编曲版本的misc。
二阳二阳,给我点钱,我要ak编曲版本的misc。
你不是ak了吗,怎么又要ak
编曲版本的更帅啊
好,儿子我支持你啊,微信转账一元c
话不多说,直接速速ak编曲版本的misc
3天后
雪殇雪殇,你网络大孝子的快递到了
拆开看一下。本身我已经是最强ctfer了,有了编曲版本misc的加成,我一定会越来越强的,加油,奥里给
没报名,非利益相关,题目有趣做做玩玩。
鸣谢(广告):
感谢谷玉阳全程提供帮助,欢迎关注,他的网易音乐人频道:Tryank - 歌手 - 网易云音乐 (163.com)
以及我社EIMSOUND网易云音乐频道:EIMSOUND - 歌手 - 网易云音乐 (163.com)
题目描述:
Sing, O Muse, of the flage of Achilles... Required reading: https://en.wikipedia.org/wiki/X-SAMPA Note: the flag is NOT in `PCTF{...}` format.解题:
首先题目附件:
![图片[1]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-1024x171.png)
一个输出音频,一个音频库,一个README,一个脚本
逐一查看,export明显可以听出前面唱的是flag,后面就听不出来了,看一下readme
install Violet Aura Split VCCV.rar in OpenUtau
run generate.py to generate song.ustx
open song.ustx in OpenUtau and export song-01.wav
(Violet Aura Split VCCV.rar from https://utau.fandom.com/wiki/Violet_Aura)
告诉了我们的流程,大概就是跑脚本,生成ustx工程文件,工程文件输出flag唱词音频
这里下载好openutau导入他给的rar音频库即可。
查看一下脚本(做题时加了几处print,不影响)
# made with OpenUtau v0.0.705.0
from secret import FLAG, MELODY
# X-SAMPA
vowels = '3AIOao{}'
consonants = '45DGLNSTfglprw'
dummy_vowel = '@'
dummy_consonant = 'h'
print(set(vowels+consonants))
print(set(FLAG))
assert(set(vowels+consonants) == set(FLAG))
assert(len(FLAG) == 29)
diphones = []
# convert to CVCVCV...
diphone = ''
for i in FLAG:
if len(diphone) == 0:
if i in vowels:
diphones.append(dummy_consonant + i)
else:
diphone = i
else:
if i in vowels:
diphones.append(diphone + i)
diphone = ''
else:
diphones.append(diphone + dummy_vowel)
diphone = i
if len(diphone) > 0:
diphones.append(diphone + dummy_vowel)
print(MELODY)
print(diphones)
assert len(MELODY) == len(diphones)
header = '''name: flagsong
comment: ''
output_dir: Vocal
cache_dir: UCache
ustx_version: 0.5
bpm: 120
beat_per_bar: 4
beat_unit: 4
resolution: 480
expressions:
dyn:
name: dynamics (curve)
abbr: dyn
type: Curve
min: -240
max: 120
default_value: 0
is_flag: false
flag: ''
pitd:
name: pitch deviation (curve)
abbr: pitd
type: Curve
min: -1200
max: 1200
default_value: 0
is_flag: false
flag: ''
clr:
name: voice color
abbr: clr
type: Options
min: 0
max: -1
default_value: 0
is_flag: false
options: []
eng:
name: resampler engine
abbr: eng
type: Options
min: 0
max: 1
default_value: 0
is_flag: false
options:
- ''
- worldline
vel:
name: velocity
abbr: vel
type: Numerical
min: 0
max: 200
default_value: 100
is_flag: false
flag: ''
vol:
name: volume
abbr: vol
type: Numerical
min: 0
max: 200
default_value: 100
is_flag: false
flag: ''
atk:
name: attack
abbr: atk
type: Numerical
min: 0
max: 200
default_value: 100
is_flag: false
flag: ''
dec:
name: decay
abbr: dec
type: Numerical
min: 0
max: 100
default_value: 0
is_flag: false
flag: ''
gen:
name: gender
abbr: gen
type: Numerical
min: -100
max: 100
default_value: 0
is_flag: true
flag: g
genc:
name: gender (curve)
abbr: genc
type: Curve
min: -100
max: 100
default_value: 0
is_flag: false
flag: ''
bre:
name: breath
abbr: bre
type: Numerical
min: 0
max: 100
default_value: 0
is_flag: true
flag: B
brec:
name: breathiness (curve)
abbr: brec
type: Curve
min: -100
max: 100
default_value: 0
is_flag: false
flag: ''
lpf:
name: lowpass
abbr: lpf
type: Numerical
min: 0
max: 100
default_value: 0
is_flag: true
flag: H
mod:
name: modulation
abbr: mod
type: Numerical
min: 0
max: 100
default_value: 0
is_flag: false
flag: ''
alt:
name: alternate
abbr: alt
type: Numerical
min: 0
max: 16
default_value: 0
is_flag: false
flag: ''
shft:
name: tone shift
abbr: shft
type: Numerical
min: -36
max: 36
default_value: 0
is_flag: false
flag: ''
shfc:
name: tone shift (curve)
abbr: shfc
type: Curve
min: -1200
max: 1200
default_value: 0
is_flag: false
flag: ''
tenc:
name: tension (curve)
abbr: tenc
type: Curve
min: -100
max: 100
default_value: 0
is_flag: false
flag: ''
voic:
name: voicing (curve)
abbr: voic
type: Curve
min: 0
max: 100
default_value: 100
is_flag: false
flag: ''
tracks:
- singer: Violet Aura Split VCCV
phonemizer: OpenUtau.Core.DefaultPhonemizer
mute: false
solo: false
volume: 0
voice_parts:
- name: New Part
comment: ''
track_no: 0
position: 0
notes:
'''
footer = ''' curves: []
wave_parts: []
'''
note = ''' - position: {}
duration: {}
tone: {}
lyric: {}
pitch:
data:
- {{x: -40, y: {}, shape: io}}
- {{x: 40, y: 0, shape: io}}
snap_first: true
vibrato: {{length: 75, period: 175, depth: 25, in: 10, out: 10, shift: 0, drift: 0}}
note_expressions: []
phoneme_expressions: []
phoneme_overrides: []
'''
song = ''
position = 0
prev_tone = MELODY[0][0]
for lyric, (tone, duration) in zip(diphones, MELODY):
assert duration % 240 == 0
song += note.format(position, duration, tone, lyric, (prev_tone-tone)*10)
position += duration
prev_tone = tone
with open('song2.ustx','w') as f:
f.write(header + song + footer)
print(FLAG)重点分析这几处
![图片[2]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-1-923x1024.png)
第一处整体逻辑如下,首先utau是一款声音合成工具,他所基于的原理就是对各种元音辅音进行拼接来发出具体声音,实现说话效果。题目中所采用的是X-SAMPA的发音字母表,重点观察{}@这三个元音就行了
![图片[3]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-2-1024x153.png)
从代码的逻辑来讲,如果flag中字符表为元音本身,那么就会在前面加上h,例如I,则会变成hI发音
如果为一个辅音+一个元音,那么就会pass,直接就组合,例如SA
如果为一个辅音,那么结尾自动加@,例如S@
这里理解后就要继续进行
拉到最下,从hearder开始的大批字符串,直到最后的note才是重中之重
![图片[4]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-3-1024x270.png)
![图片[5]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-4-1024x653.png)
可以用openutau自行生成一个工程文件,记事本打开结合来看,更加清晰
总之有变动的就是note,也就是钢琴窗所摆放的位置,结合文件结构和代码分析,重点关注圈中的三个参数即可。
(玩过fl等编曲工具的应该好理解下面的参数)
![图片[6]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-5.png)
duration为单个note的长度,tone为轨道数,lyric则是歌词。轨道数经过测试,当tone为0时,钢琴窗位置则是c-1
![图片[7]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/HGXGXL04BR345867WYZG1-1024x96.png)
以此类推,C6的位置就是84,接下来通过对原音频的扒带,把tone参数和duration参数给获取出来
![图片[8]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/G7FBHG7BHYLAL9FZ3RWG-1024x373.png)
将其转换为题目中的MELODY封装,如下
ME2 = [480,480,480,240,240,480,480,480,480,480,480,480,240,240,480,480,480,480,960]
ME1 = [69, 64, 72, 71, 69, 71, 67, 62, 71, 65, 60, 69, 67, 65, 67, 69, 71, 74, 72]
MELODY = list(zip(ME1, ME2))
FLAG = '' #先随便写点,长度跟ME1一样
这时,原代码可以看出来
![图片[9]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-6.png)
flag总长度为29,以及flag字符集是始终在上面的元音和辅音的字符集中。根据音频听可以明显听出前面唱的是flag{,那么做个测试,
ME2 = [480,480,480]
ME1 = [69, 64, 72]
MELODY = list(zip(ME1, ME2))
FLAG = 'flag{' #先随便写点,长度跟ME1一样注释掉源程序中的assert
运行代码,生成ustx,导入utau,播放试听(有个视频博客丢不上来,自行脑补)。
![图片[10]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-7-1024x412.png)
非常好,完全一致。那么接下来只需要通过听力和对比后续的唱词差异就可以逐步推出flag,体力活,听了五个小时
期间这里我们插入了这段代码,生成了全部可能结果将其生成音频,对比听力差异与导出后丢入pr的频谱对比。
# text = []
# for i in consonants:
# for o in vowels:
# text.append(f'{i}{o}')
# text.append(f'{i}{dummy_vowel}')
# print(text)
final:
# diphones = ['43', '4A', '4I', '4O', '4a', '4o', '4@', '53', '5A', '5I', '5O', '5a', '5o', '5@', 'D3', 'DA', 'DI', 'DO', 'Da', 'Do', 'D{', 'D}', 'D@', 'G3', 'GA', 'GI', 'GO', 'Ga', 'Go', 'G{', 'G}', 'G@', 'L3', 'LA', 'LI', 'LO', 'La', 'Lo', 'L{', 'L}', 'L@', 'N3', 'NA', 'NI', 'NO', 'Na', 'No', 'N{', 'N}', 'N@', 'S3', 'SA', 'SI', 'SO', 'Sa', 'So', 'S{', 'S}', 'S@', 'T3', 'TA', 'TI', 'TO', 'Ta', 'To', 'T{', 'T}', 'T@', 'f3', 'fA', 'fI', 'fO', 'fa', 'fo', 'f{', 'f}', 'f@', 'g3', 'gA', 'gI', 'gO', 'ga', 'go', 'g{', 'g}', 'g@', 'l3', 'lA', 'lI', 'lO', 'la', 'lo', 'l{', 'l}', 'l@', 'p3', 'pA', 'pI', 'pO', 'pa', 'po', 'p{', 'p}', 'p@', 'r3', 'rA', 'rI', 'rO', 'ra', 'ro', 'r{', 'r}', 'r@', 'w3', 'wA', 'wI', 'wO', 'wa', 'wo', 'w{', 'w}', 'w@','h3','hA','hI','hO','ha','ho','h{','h}']
# MELODY = []
# for i in diphones:
# MELODY.append((69, 480))![图片[11]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-10-1024x715.png)
![图片[12]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-8-1024x619.png)
最终反复试错重复对软件歌词的修改。获得最终的flag,以及正确的波形
![图片[13]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/image-9-1024x640.png)
ME2 = [480,480,480,240,240,480,480,480,480,480,480,480,240,240,480,480,480,480,960]
ME1 = [69, 64, 72, 71, 69, 71, 67, 62, 71, 65, 60, 69, 67, 65, 67, 69, 71, 74, 72]
# MELODY = zip(ME1, ME2)
# FLAG = 'flag{ T}' #先随便写点,长度跟ME1一样
#3AIOo45DGLNSTPrw
MELODY = list(zip(ME1, ME2))
FLAG = 'flag{N3wprA4DLoGOI5NoTaSgOOD}' #先随便写点,长度跟ME1一样
FLAG = 'flag{N3wprA4TLoGOI5NoTaSgOOD}'
#f la g{ NA
# diphones = ['43', '4A', '4I', '4O', '4a', '4o', '4@', '53', '5A', '5I', '5O', '5a', '5o', '5@', 'D3', 'DA', 'DI', 'DO', 'Da', 'Do', 'D{', 'D}', 'D@', 'G3', 'GA', 'GI', 'GO', 'Ga', 'Go', 'G{', 'G}', 'G@', 'L3', 'LA', 'LI', 'LO', 'La', 'Lo', 'L{', 'L}', 'L@', 'N3', 'NA', 'NI', 'NO', 'Na', 'No', 'N{', 'N}', 'N@', 'S3', 'SA', 'SI', 'SO', 'Sa', 'So', 'S{', 'S}', 'S@', 'T3', 'TA', 'TI', 'TO', 'Ta', 'To', 'T{', 'T}', 'T@', 'f3', 'fA', 'fI', 'fO', 'fa', 'fo', 'f{', 'f}', 'f@', 'g3', 'gA', 'gI', 'gO', 'ga', 'go', 'g{', 'g}', 'g@', 'l3', 'lA', 'lI', 'lO', 'la', 'lo', 'l{', 'l}', 'l@', 'p3', 'pA', 'pI', 'pO', 'pa', 'po', 'p{', 'p}', 'p@', 'r3', 'rA', 'rI', 'rO', 'ra', 'ro', 'r{', 'r}', 'r@', 'w3', 'wA', 'wI', 'wO', 'wa', 'wo', 'w{', 'w}', 'w@']
#45DGLNSTfglprw
#['f@', 'la', 'g{', 'N3', 'w@', 'p@', 'rA', '4@', ' @', 'Lo', ' ', 'hI', '5A', 'No', 'Ta', 'S@', 'gO', 'hO', 'D}']
最终flag:flag{N3wprA4TLoGOI5NoTaSgOOD}
![图片[14]-PlaidCTF 2022 flagsong WriteUP-魔法少女雪殇](https://cdn.snowywar.top/wp-content/uploads/2022/04/QQ截图20220409194410-1024x661.png)
我的评价:
感觉不如musc,下次我也出扒带🤭